
Old school is once daily. 365 a year. For over a century, word puzzles have been a daily affair—crosswords in newspapers since 1913, now Connections at the Times and Pinpoint at LinkedIn.

See also: Handcrafting doesn’t scale — At the New York Times, Wyna Liu needs at least 2.5 hours per Connections puzzle, and her constraint notebook is growing. Wordle is recycling answers, and Spelling Bee has been “dumpster diving” for new words.
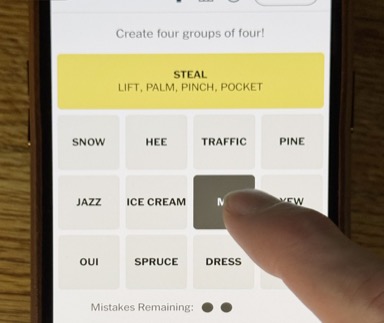
The New York Times ships one small puzzle a day—a 4×4 board, a single solution, built by a brilliant constructor. Wyna Liu spends two and a half hours on each Connections board and says it never gets easier. This is slow and unscalable, but they don’t care. They monetize subscriptions and engagement, not the games directly. They only need 365 levels a year.
A mobile studio has different needs. Players expect a tap experience with larger boards, layered mechanics, and enough levels to retain them for months. That means 8 to 15 categories per board, thousands of levels, real monetization. If Wyna Liu needs two and a half hours for a satisfying 4×4, how long does a 10×5 take? A 15×5? And how much longer to validate that every row is clean?
The puzzlemaking team uses up easier topics. Puzzles need to be internally mutually exclusive—no overlapping answers across categories. Cross-checking every word against every other category is computationally hard. LLMs can’t sustain it: they collapse toward the same popular topics and can’t maintain consistency across levels. Your highest-LTV players notice the repetition first. They stop playing. That’s revenue left on the table.
The genre lives or dies on its content. Let’s look deeper at why scaling is so hard:











